”算法 机器学习 聚类 生活 文档资料“ 的搜索结果
资料说明:包括数据+代码+文档+代码讲解。 1.项目背景 2.数据获取 3.数据预处理 4.探索性数据分析 5.特征工程 6.构建聚类模型 7.结论与展望
聚类算法是机器学习中一种重要的无监督学习算法,它的目的是将一组数据分成几个簇,使得同一个簇内的数据点之间相似度高,而不同簇内的数据点相似度低。聚类算法广泛应用于数据挖掘、图像分割、市场细分等领域。选择...
2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载学习,也适合小白学习进阶,当然也可作为毕设项目、课程设计、作业、项目初期立项演示等。...
聚类算法在机器学习中应用广泛,但其性能可能会受到一些因素的影响,例如数据噪声、数据分布不均匀、参数设置不合理等。聚类算法的优化是一个复杂的问题,需要根据具体的应用场景进行调整。常用的优化措施包括数据...
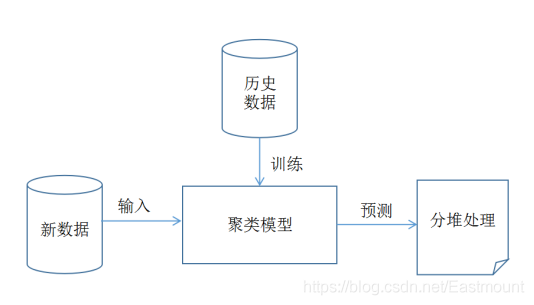
1. 为什么学习聚类算法 在没有具体类别标签列或结果的前提下,我们还希望对已有的数据进行分类,这时候就需要使用聚类方法。 1.1 聚类方法案例引入 (1)两个人在话筒前面同时说话,录音后发现这两个人的声音混杂在...
文章目录1 概述1.1 无监督学习与聚类算法1.2 sklearn中常用的聚类算法2 sklearn中生成测试数据函数介绍2.1 make_classification2.2 make_moons2.3 make_moons2.4 make_blobs3 使用sklearn聚类示例3.1 簇数据聚类3.2 ...
将城市名转化为经纬度后进行Kmeans算法聚类并可视化
机器学习之聚类
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目13-基于K-means算法的文本聚类分析,生成文本聚类后的文件。文本聚类分析是NLP领域的一个核心任务,通过将相似的文本样本分组,可以帮助我们发现隐藏在...

聚类属于典型的无监督学习(Unsupervised Learning) 方法。与监督学习(如分类器)相比,无监督学习的训练集没有人为标注的结果。在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
【机器学习项目实战】Python实现聚类(Kmeans)分析客户分组 资料说明:包括数据集+源代码+Word文档说明。 资料内容包括: 1)问题定义; 2)数据收集; 3)数预处理; 4)探索性数据分析; 5)聚类模型; 6)聚类可视化...
本课程适合所有需要学习机器学习技术的同学,课件内容制作精细,由浅入深,适合入门或进行知识回顾。 本章为该课程的其中一个章节,如有需要可下载全部课程 全套资源下载地址:...
聚类属于无监督学习,对大量未标注的数据集,按照数据内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小。 给定一个有N个对象的数据集,构造数据的K个簇,K≤N,同时满足,每个...

DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个出现得比较早(1996年),比较有代表性的基于密度的聚类算法。DBSCAN能够将足够高密度的区域划分成簇,并能在具有噪声的空间数据库中...

聚类和相似度 1、[找到一种自动索引检索他感兴趣文章的方法] 1、如何衡量文章之间的相似度(需要一种度量手段) 2、怎样在全部的文章中搜索出下一篇要推荐的文章 2、如何表示一篇文档 词袋模型(忽略文档中单词的...

本文对基于 机器 学 习 的 轨迹预测 方法进 行研 究 , 主要完 成 了 如下 工 作 : 研 宄 了 轨迹 信 息 的 处理方法 。 通 过轨迹 预处理 、 空 间 信 息提取 、 时 间 和 方 向 信 息 添加 等系 列 流程 , 将 ...
聚类的应用场景没有分类广泛,而由于无监督其算法效果也不足已运用到生产环境中去,不过其仍然是机器学习中的一个重要组成部分。文本聚类常见的应用场景就是文档标签生成,热点新闻发现等等,另外,在处理文本特征时...

这类算法能克服基于距离的算法只能发现“类圆形”(凸)的聚类的缺点,可发现任意形状的聚类, 且对噪声数据不敏感。但计算密度单元的计算复杂 度大,需要建立空间索引来降低计算量。 DBSCAN DBSCAN(Density-Based ...
聚类算法介绍,及论文推导过程,其中有详细的解析过程。
聚类分析是一种典型的无监督学习, 用于对未知类别的样本进行划分,将它们按照一定的规则划分成若干个类族,把相似(距高相近)的样本聚在同一个类簇中, 把不相似的样本分为不同类簇,从而揭示样本之间内在的性质以及...
机器学习实战之路 —— 6 聚类算法1. 聚类相关基本概述1.1 学习模式1.1.1 监督学习1.1.2 无监督学习1.2 聚类分析1.2.1 基本概念1.2.2 基本步骤1.2.3 相似性度量1.2.3.1 距离度量1.2.3.1 相似系数度量1.2.4 有效性...

02 人工智能实验--kmeans算法对图片的像素点进行聚类 03 人工智能实验--knn算法手写数字的笔迹识别 04 人工智能实验--基于物品的协同过滤算法 05 人工智能实验--基于用户的协同过滤算法 06 人工智能实验--基于决策树...
1、资源内容:基于密度峰值的聚类算法的matlab,k-means,DB-SCAN+源代码+文档说明+数据集 2、代码特点:内含运行结果,不会运行可私信,参数化编程、参数可方便更改、代码编程思路清晰、注释明细,都经过测试运行...
推荐文章
- confluence搭建部署_ata confluence-程序员宅基地
- SpringCloud与SpringBoot版本对应关系_springboot 2.1.1 对于的cloud-程序员宅基地
- 如何恢复硬盘数据?简单解决问题_磁盘恢复 csdn-程序员宅基地
- 苹果手机测试网络速度的软件,App Store 上的“网速测试大师-测网速首选”-程序员宅基地
- 教了一年少儿编程,说说感想和体验-程序员宅基地
- 22东华大学计算机专硕854考研上岸实录-程序员宅基地
- 如何用《玉树芝兰》入门数据科学?-程序员宅基地
- macOS使用brew包管理器_brew清理缓存-程序员宅基地
- 【echarts没有刷新】用按钮切换echarts图表的时候,该消失的图表还在,加个key属性就解决了_echarts 怎么加key值-程序员宅基地
- 常用机器学习的模型和算法_常见机器学习模型算法整理和对应超参数表格整理-程序员宅基地